






智測﹒工業(yè)設(shè)備故障預(yù)測分析系統(tǒng)
一、企業(yè)簡介
智擎信息技術(shù)(北京)有限公司專注于工業(yè)大數(shù)據(jù),利用物聯(lián)網(wǎng)和機(jī)器學(xué)習(xí)技術(shù)為工業(yè)企業(yè)提供設(shè)備數(shù)據(jù)采集、智能監(jiān)控、故障預(yù)警、 自診斷、產(chǎn)線效能優(yōu)化、運(yùn)維管理分析、大部件庫存優(yōu)化分析、銷量預(yù)測等產(chǎn)品和服務(wù)。產(chǎn)品能夠提供基于公有云及私有云的落地實(shí)施。
智擎信息提供針對工業(yè)領(lǐng)域深度定制的分析模型軟件套件產(chǎn)品,涵蓋了設(shè)備預(yù)測性運(yùn)維、自診斷、設(shè)備性能優(yōu)化、成本分析、供應(yīng)鏈分析等,并具有機(jī)器學(xué)習(xí)自建模等一系列功能和服務(wù)。為企業(yè)管理者提供戰(zhàn)略性的決策支持。智擎信息致力于成為中國乃至全球領(lǐng)先的工業(yè)設(shè)備及生產(chǎn)線智能分析平臺和預(yù)測服務(wù)提供商。
我們工業(yè)APP產(chǎn)品是基于Hadoop和 Spark開源生態(tài)建立而來。在機(jī)器學(xué)習(xí)建模和分析方面,我們將深度學(xué)習(xí)和機(jī)器學(xué)習(xí)同行業(yè)知識圖譜相融合形成了針對工業(yè)領(lǐng)域的動(dòng)態(tài)閾值深度學(xué)習(xí)算法。我們優(yōu)化了深度神經(jīng)網(wǎng)絡(luò)(例如:LSTM 模型),并將故障樹、故障診斷機(jī)理等信息植入到深度神經(jīng)網(wǎng)絡(luò)的增量、增強(qiáng)學(xué)習(xí)之中。我們獨(dú)創(chuàng)了工業(yè)領(lǐng)域的自動(dòng)化建模方法。此自動(dòng)化建模機(jī)制針對工業(yè)領(lǐng)域中的溫度、振動(dòng)、 壓力、轉(zhuǎn)速,以及大部件的失效進(jìn)行了優(yōu)化,實(shí)現(xiàn)了高準(zhǔn)確 率的自動(dòng)化調(diào)參和建模機(jī)制。
二、工業(yè)APP簡介
(一)、問題定位
近些年隨著國內(nèi)工業(yè)制造業(yè)飛速的發(fā)展對設(shè)備管理提出了更高的要求。在設(shè)備管理和生產(chǎn)線優(yōu)化方面,隨著設(shè)備老化程度的持續(xù)提高和對生產(chǎn)效率的新要求,很多客戶需要一套完整的工業(yè)大數(shù)據(jù)平臺來支撐他們從設(shè)備運(yùn)行監(jiān)控管理、預(yù)測分析和運(yùn)營決策支撐。
本產(chǎn)品覆蓋了數(shù)據(jù)的采集、數(shù)據(jù)的機(jī)器學(xué)習(xí)建模訓(xùn)練、預(yù)測分析模型運(yùn)行環(huán)境、模型庫管理、設(shè)備健康度分析功能、故障預(yù)測模型創(chuàng)建和分析功能、故障樹分析、處理措施推薦及窗口期功能等主要解決了如下問題:降低故障頻次及非計(jì)劃性停機(jī)時(shí)間、提升設(shè)備產(chǎn)能、對設(shè)備進(jìn)行全生命周期的管理。
(二)、創(chuàng)新點(diǎn)
本產(chǎn)品可以通過公有云、私有化部署和混合云的方式部署實(shí)現(xiàn)。同時(shí),可以通過移動(dòng)端的方式為用戶提供服務(wù)。產(chǎn)品特性涵蓋了歷史數(shù)據(jù)的機(jī)器學(xué)習(xí)自動(dòng)化建模(故障預(yù)測模型、關(guān)聯(lián)性故障模型、大部件生存分析模型)、SaaS化的設(shè)備故障預(yù)測APP應(yīng)用落地等。主要優(yōu)勢如下:
1、針對故障和診斷的自動(dòng)化建模和調(diào)優(yōu)機(jī)制。產(chǎn)品內(nèi)置了針對行業(yè)具體應(yīng)用場景而優(yōu)化的自動(dòng)化建模和模型調(diào)優(yōu)機(jī)制,融合了經(jīng)過行業(yè)認(rèn)可的模型參數(shù)庫和知識圖譜機(jī)制,可以根據(jù)更新的參數(shù)和知識圖譜進(jìn)行自動(dòng)化優(yōu)化從而創(chuàng)建新模型。讓設(shè)備專家針對模型的創(chuàng)建和優(yōu)化時(shí)間縮短到數(shù)小時(shí)內(nèi)。
2、可以針對不同的設(shè)備進(jìn)行多樣性模型的部署和管理。也可以針對位于不同工況下的同類設(shè)備部署不同版本的模型,便于更好的模型適配和預(yù)測準(zhǔn)確度。
3、可靠性:考慮到同工業(yè)互聯(lián)網(wǎng)平臺的適配,在整個(gè)數(shù)據(jù)倉庫的架構(gòu)設(shè)計(jì)中,引入Hadoop生態(tài)系統(tǒng)的多個(gè)組件,對于整個(gè)Hadoop集群,以及每個(gè)生態(tài)組件,都設(shè)計(jì)的故障轉(zhuǎn)移機(jī)制或者集群。最大程度的保證服務(wù)的連續(xù)性,以及出現(xiàn)故障的自動(dòng)轉(zhuǎn)移。
4、可擴(kuò)展性:在 Hadoop 生態(tài)系統(tǒng)中各個(gè)組件自身均支持分布式部署,在可擴(kuò)展性方面每個(gè)組件均支持在線的擴(kuò)展性,非常容易進(jìn)行新的節(jié)點(diǎn)和資源的增加,對于集群的管理引入Apache Ambari進(jìn)行管理,可以方便地部署組件以及進(jìn)行節(jié)點(diǎn)的擴(kuò)展。在負(fù)載和主節(jié)點(diǎn)的冗余機(jī)制中引入 Apache Zookeeper,更易于管理主節(jié)點(diǎn)的可靠性。
5、部署靈活性:在設(shè)計(jì)方案中可采用云服務(wù)及私有化部署的方式,在Hadoop集群的搭建時(shí)采用Hadoop以及各個(gè)開源組件。
6、易用性:在易用性的設(shè)計(jì)上面,針對用戶可見的操作均設(shè)計(jì)為簡單操作使用,用戶可以按照操作手冊簡單的學(xué)習(xí)后即可操作。數(shù)據(jù)模型的創(chuàng)建也都是通過可視化的配置來完 成的。
7、安全性:在數(shù)據(jù)展示端的B/S架構(gòu)系統(tǒng)中采用 Apache Shiro 安全框架進(jìn)行安全和身份認(rèn)證的管理,對于不同角色的人員進(jìn)行功能使用的控制,對于數(shù)據(jù)的訪問按照區(qū)域進(jìn)行數(shù)據(jù)隔離。
(三)、功能介紹
產(chǎn)品功能包含了數(shù)據(jù)接入、數(shù)據(jù)管理、模型管理、故障 預(yù)測、儀表盤管理、模型調(diào)度、診斷和自動(dòng)化等功能。
數(shù)據(jù)接入:通過數(shù)據(jù)采集終端從設(shè)備上把傳感器的數(shù)據(jù)采集出來,或者從客戶方已經(jīng)采集出來的數(shù)據(jù)進(jìn)行數(shù)據(jù)轉(zhuǎn)發(fā),最終進(jìn)行大數(shù)據(jù)平臺的數(shù)據(jù)接入,其中傳輸?shù)倪^程包含了數(shù)據(jù)的壓縮和加密。
圖1 數(shù)據(jù)接入界面
數(shù)據(jù)管理:針對實(shí)時(shí)接入的設(shè)備傳感器數(shù)據(jù)、批量導(dǎo)入的歷史數(shù)據(jù)、以及用戶自由上傳的文件數(shù)據(jù)進(jìn)行統(tǒng)一接入、處理和存儲等一體化的管理。
圖2 數(shù)據(jù)管理界面
模型管理:包含模型的建模過程管理、模型測試、模型評估、模型上線部署、模型調(diào)度運(yùn)行等,從模型的創(chuàng)建、訓(xùn)練、測試、部署、上線全鏈路流程功能的覆蓋。
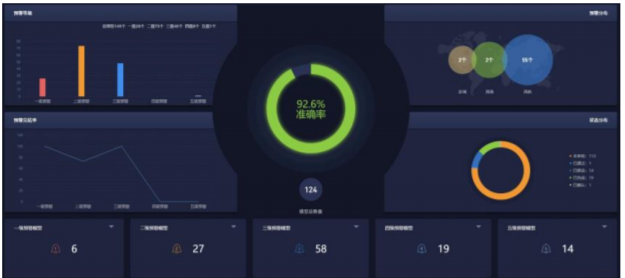
圖3 模型管理界面
故障預(yù)測:通過特定故障場景進(jìn)行模型的建模訓(xùn)練,完成訓(xùn)練后的模型上線部署,可以針對該故障進(jìn)行故障發(fā)生的提前預(yù)測,在預(yù)測到故障的發(fā)生,即生成故障的預(yù)警,針對故障的預(yù)警可以由專業(yè)的人員進(jìn)行審核并 下發(fā)到現(xiàn)場進(jìn)行故障預(yù)警的排查與檢修。

圖4 故障預(yù)測界面
儀表盤管理:針對數(shù)據(jù)的可視化,儀表盤是數(shù)據(jù)最終呈現(xiàn)的方法,可以支持歷史數(shù)據(jù)、實(shí)時(shí)數(shù)據(jù)、上傳的文本數(shù)據(jù),以及故障數(shù)據(jù),主數(shù)據(jù)、故障預(yù)警數(shù)據(jù)等進(jìn)行可視化展示,操作方便,支持多種類型的圖標(biāo)構(gòu)建。
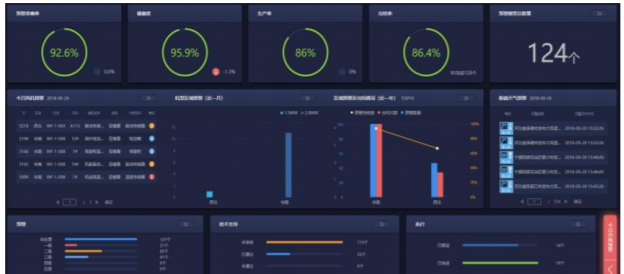
圖5 儀表盤管理界面
模型調(diào)度:模型調(diào)度是針對不同設(shè)備的實(shí)時(shí)數(shù)據(jù),針對不同的模型進(jìn)行定時(shí)調(diào)度執(zhí)行的管理功能。
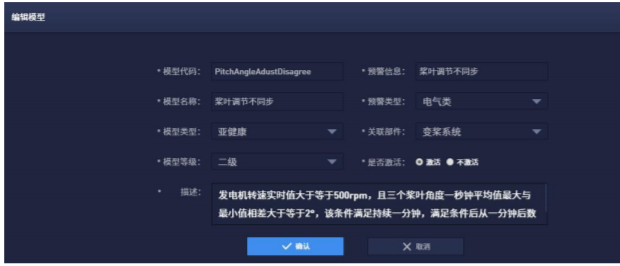
圖6 模型調(diào)度界面
診斷和自動(dòng)化:故障預(yù)測模型針對不同的故障場景或者不同的設(shè)備部件進(jìn)行預(yù)測后,生成的預(yù)警會關(guān)聯(lián)到特定的設(shè)備和部件上,并且針對不同模型的排查與診斷提供方案。 針對模型的自動(dòng)化包括自動(dòng)化建模和模型上線后的增量自動(dòng)化優(yōu)化。
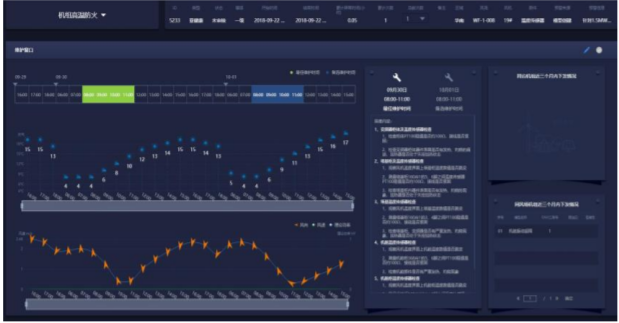
圖7 故障診斷及運(yùn)維指導(dǎo)界面
(四)、功能和技術(shù)指標(biāo)優(yōu)勢
1、提升模型分析和預(yù)測的準(zhǔn)確率:通過自動(dòng)化參數(shù)調(diào)整和增量/增強(qiáng)學(xué)習(xí)將預(yù)測準(zhǔn)確度指標(biāo)提升5%。同時(shí),對遷移學(xué)習(xí)的應(yīng)用,在未進(jìn)行預(yù)訓(xùn)練狀況下,也可以達(dá)到較為準(zhǔn)確的預(yù)測值;
2、統(tǒng)一數(shù)據(jù)總線層:統(tǒng)一設(shè)計(jì)數(shù)據(jù)接入及數(shù)據(jù)存儲層,并形成統(tǒng)一的接口總線,從而建立標(biāo)準(zhǔn)化的數(shù)據(jù)管理流程。
3、統(tǒng)一業(yè)務(wù)分析層:實(shí)現(xiàn)統(tǒng)一的針對業(yè)務(wù)的機(jī)器學(xué)習(xí)算法/模型調(diào)用層,最終實(shí)現(xiàn)從數(shù)據(jù)接入和處理、模型算法分析預(yù)測到展示的集中管理。
4、產(chǎn)品提供多種編程語言接口:Java/Scala/Python/R 等。支持基于分布式 R 和 Python 等主流數(shù)據(jù)分析軟件。
三、技術(shù)方案說明
(一)、工業(yè)APP架構(gòu)
本產(chǎn)品基于Hadoop大數(shù)據(jù)平臺基礎(chǔ)之上,利用Hadoop構(gòu)建分布式集群,進(jìn)行數(shù)據(jù)的分布式存儲,利用spark構(gòu)建分布式計(jì)算框架,進(jìn)行數(shù)據(jù)和模型的分布式計(jì)算,利用Hive和HBase搭建數(shù)據(jù)倉庫,自研發(fā)數(shù)據(jù)處理和管理組件。
機(jī)器學(xué)習(xí)算法模型利用tensorflow構(gòu)建深度學(xué)習(xí)模型訓(xùn)練框架,自研發(fā)自組織自動(dòng)化數(shù)據(jù)標(biāo)記算法,自研發(fā)分布式模型執(zhí)行運(yùn)算調(diào)度框架,自研發(fā)自動(dòng)化故障建模框架。產(chǎn)品架構(gòu)設(shè)計(jì)如下:

圖8 工業(yè)設(shè)備故障預(yù)測分析系統(tǒng)APP架構(gòu)圖
智能終端做為智擎工業(yè)設(shè)備數(shù)據(jù)采集運(yùn)算終端,可以與設(shè)備PLC 通信,把傳感器的實(shí)時(shí)數(shù)據(jù),錄波數(shù)據(jù)采集出來,并且作為端的運(yùn)算終端,針對實(shí)時(shí)的數(shù)據(jù)進(jìn)行初步的運(yùn)算,然后進(jìn)行大數(shù)據(jù)平臺的數(shù)據(jù)接入,可以支持?jǐn)?shù)據(jù)的斷點(diǎn)續(xù)傳。WYSEngine SDK Apollo 作為產(chǎn)品數(shù)據(jù)接口的 SDK 組件,運(yùn)行與 Hadoop 大數(shù)據(jù)平臺執(zhí)行,按照工業(yè)設(shè)備的數(shù)據(jù)應(yīng)用場景進(jìn)行功能組件的封裝,實(shí)現(xiàn)從數(shù)據(jù)的接入、數(shù)據(jù)處理、數(shù)據(jù)存儲、數(shù)據(jù)運(yùn)算、模型管理和任務(wù)調(diào)度等功能,為上層應(yīng)用提供平臺級的支撐。
此外,APP 產(chǎn)品功能覆蓋了針對數(shù)據(jù)的管理,模型管理,模型庫,應(yīng)用儀表盤,模型評估和模型調(diào)度,并且封裝一系列針對工業(yè)場景優(yōu)化的算法和業(yè)務(wù)場景。
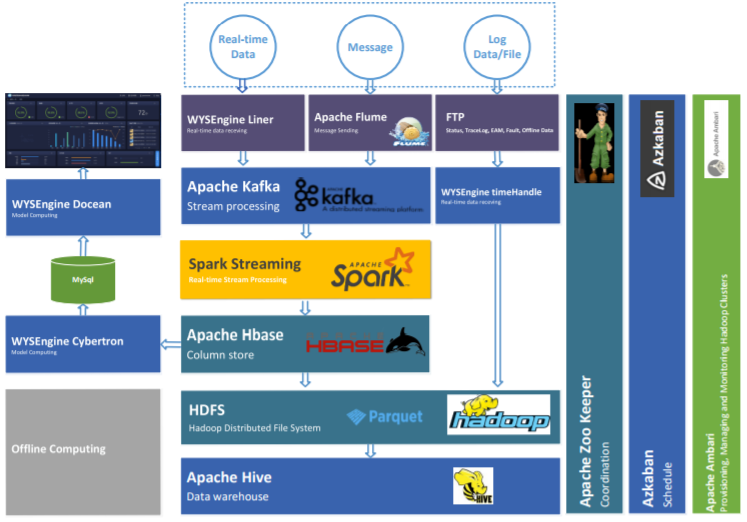
圖9 工業(yè)設(shè)備故障預(yù)測分析系統(tǒng)APP組件圖
HDFS 作為實(shí)時(shí)數(shù)據(jù)和歷史數(shù)據(jù)的存儲平臺,使用服務(wù)器集群進(jìn)行部署,HDFS中的文件存儲采用Apache Parquet的存儲格式進(jìn)行存儲,最大程度上進(jìn)行數(shù)據(jù)的壓縮存儲,并且保證數(shù)據(jù)使用時(shí)真實(shí)性。 Apache Hadoop Yarn作為整個(gè)Hadoop集群的資源管理器, 對所有計(jì)算任務(wù)所需要的資源進(jìn)行調(diào)度管理,并針對集群資源進(jìn)行管理。
Apache Zookeeper 是一個(gè)分布式的分布式應(yīng)用程序協(xié)調(diào)服務(wù),可以為分布式應(yīng)用提供一致性服務(wù),作為 HDFS的NameNode主備的管理,針對Kafka集群的協(xié)調(diào)管理,針對Spark集群的協(xié)調(diào)管理。
數(shù)據(jù)倉庫的實(shí)時(shí)數(shù)據(jù)采集部分由 Flume 完成,F(xiàn)lume 對外提供 API,由外部程序調(diào)用 API 進(jìn)行數(shù)據(jù)的傳輸,F(xiàn)lume接收到的數(shù)據(jù)放入 Apache Kafka 的消息隊(duì)列中進(jìn)行緩存,以同步數(shù)據(jù)采集與數(shù)據(jù)處理存儲的速度不一致性;
文件日志數(shù)據(jù)的采集方位為開放 FTP共享文件夾,由外10部程序進(jìn)行日志數(shù)據(jù)的寫入,F(xiàn)lume監(jiān)控文件夾,對新寫入的數(shù)據(jù)進(jìn)行處理并存入HDFS中。
數(shù)據(jù)處理 ETL部分的內(nèi)容由 Spark Streaming 進(jìn)行處理,處理完成后將數(shù)據(jù)存儲到 HDFS中,另外,處理完成的數(shù)據(jù)進(jìn)行后續(xù)的計(jì)算。
分析部分在數(shù)據(jù) ETL 清洗之后進(jìn)行特征選擇、知識圖譜特征的融合、機(jī)器學(xué)習(xí)模型訓(xùn)練、模型評估、模型保存和基于效果機(jī)制的增量增強(qiáng)學(xué)習(xí),最終開放成為 API 供調(diào)用。
整個(gè)運(yùn)算部分的內(nèi)容由 Spark 集群進(jìn)行處理,處理后的結(jié)果數(shù)據(jù)寫入 MySql 數(shù)據(jù)庫,以供展示系統(tǒng)抽取數(shù)據(jù)并進(jìn)行展示。展示端的直接短接 MySql 數(shù)據(jù)庫,需要確保 MySql 數(shù)據(jù)庫中的數(shù)據(jù)保持的是小量級,匯總或者處理后的數(shù)據(jù),以確保最終的展示端應(yīng)用的響應(yīng)速度。對于數(shù)據(jù)的查詢和使用主要提供 Spark SQL、Hive 組件 支持類傳統(tǒng) SQL 的數(shù)據(jù)查詢。
實(shí)時(shí)數(shù)據(jù)指從設(shè)備現(xiàn)場的工業(yè)設(shè)備中采集的實(shí)時(shí)數(shù)據(jù), 按照點(diǎn)位進(jìn)行采集,每個(gè)點(diǎn)位包含點(diǎn)位的名稱、內(nèi)容、時(shí)間 戳等字段,不同機(jī)型的工業(yè)設(shè)備采用的點(diǎn)位配置表不同,不 同的風(fēng)場的工業(yè)設(shè)備,或者相同機(jī)型的不同的工業(yè)設(shè)備所使 用的點(diǎn)位配置表也不同。
(二)、工業(yè)APP關(guān)鍵技術(shù)
在關(guān)鍵技術(shù)路線方面,主要引入了在線、離線相融合的復(fù)雜調(diào)度方式。這種方式將比較高效的解決數(shù)據(jù)接入、建模計(jì)算和實(shí)時(shí)預(yù)測各個(gè)方面的資源調(diào)度難題。尤其是針對深度學(xué)習(xí)的建模和自學(xué)習(xí)過程,將有效的避免波峰波谷過于明顯的問題。
在模型創(chuàng)建和分析預(yù)測方面,我們使用了深度學(xué)習(xí)、機(jī)器學(xué)習(xí)、知識圖譜相結(jié)合的方式。在深度學(xué)習(xí)方面,我們使 用 LSTM 等算法,以及使用了增量和增強(qiáng)學(xué)習(xí)用于自動(dòng)化建模和調(diào)優(yōu)。
對于準(zhǔn)確率的判別方面,我們利用了混淆矩陣來進(jìn)行,主要技術(shù)方面利用內(nèi)存技術(shù)、MPP 存儲共同優(yōu)化大數(shù)據(jù)平臺的瓶頸問題。
此外,冷熱數(shù)據(jù)存儲和對機(jī)器學(xué)習(xí)自學(xué)習(xí)方面都提供強(qiáng)有力的支撐,尤其是對增量學(xué)習(xí)和遷移學(xué)習(xí)方面, 平臺可以存儲相關(guān)的可變參數(shù)模板來提升算法模型準(zhǔn)確率。
四、應(yīng)用情況描述
(一)、應(yīng)用場景描述
開展設(shè)備運(yùn)行現(xiàn)場精益運(yùn)維管理,對現(xiàn)場運(yùn)維期的業(yè)務(wù)進(jìn)行細(xì)化,將數(shù)據(jù)分析、資產(chǎn)管理、故障預(yù)測和診斷、設(shè)備KPI管理、物資保障和作業(yè)窗口等集中在一起,作為基礎(chǔ)數(shù)據(jù),結(jié)合現(xiàn)場運(yùn)維策略,將現(xiàn)場工作任務(wù)進(jìn)行綜合管理,降低設(shè)備運(yùn)維成本(減小備品備件損失和更換頻次)、降低設(shè)備故障頻次和停機(jī)時(shí)間,提高設(shè)備可利用率及收益。其中,重點(diǎn)實(shí)現(xiàn)機(jī)組故障自診斷分析,推送合適作業(yè)窗口、備件位置、數(shù)量信息及故障解決方案;實(shí)現(xiàn)對現(xiàn)場KPI的管理,給現(xiàn)場運(yùn)維計(jì)劃提供數(shù)據(jù)支撐。以上信息均以工單的形式下發(fā)至設(shè)備現(xiàn)場,解決了現(xiàn)有的工單不能自動(dòng)創(chuàng)建、備件位置和數(shù)量查詢繁瑣等問題,改善了故障處理效率,降低了設(shè)備損失及運(yùn)維成本。
(二)商業(yè)化情況
本產(chǎn)品主要應(yīng)用在發(fā)電行業(yè)和石化領(lǐng)域,在發(fā)電行業(yè)的客戶有金風(fēng)、明陽、上海電氣,在石化領(lǐng)域的客戶有中海油。
本產(chǎn)品幫助用戶降低故障頻次及非計(jì)劃性停機(jī)時(shí)間、提升設(shè)備產(chǎn)能、對設(shè)備進(jìn)行全生命周期的管理。幫助用戶降低非計(jì)劃性停機(jī)時(shí)間達(dá)到19%(平均),降低故障頻次達(dá)到21%(平均)。降低直接成本消耗。此外,促進(jìn)客戶的信息化平臺的統(tǒng)一性,數(shù)據(jù)管理的一致性都起到非常重要的作用。
本產(chǎn)品幫助公司針對不同客戶的服務(wù)投入減小40%,并且可以提升運(yùn)算和模型自優(yōu)化準(zhǔn)確度。針對不同行業(yè)客戶的項(xiàng)目交付成本將減少40%,利潤增加15%以上。
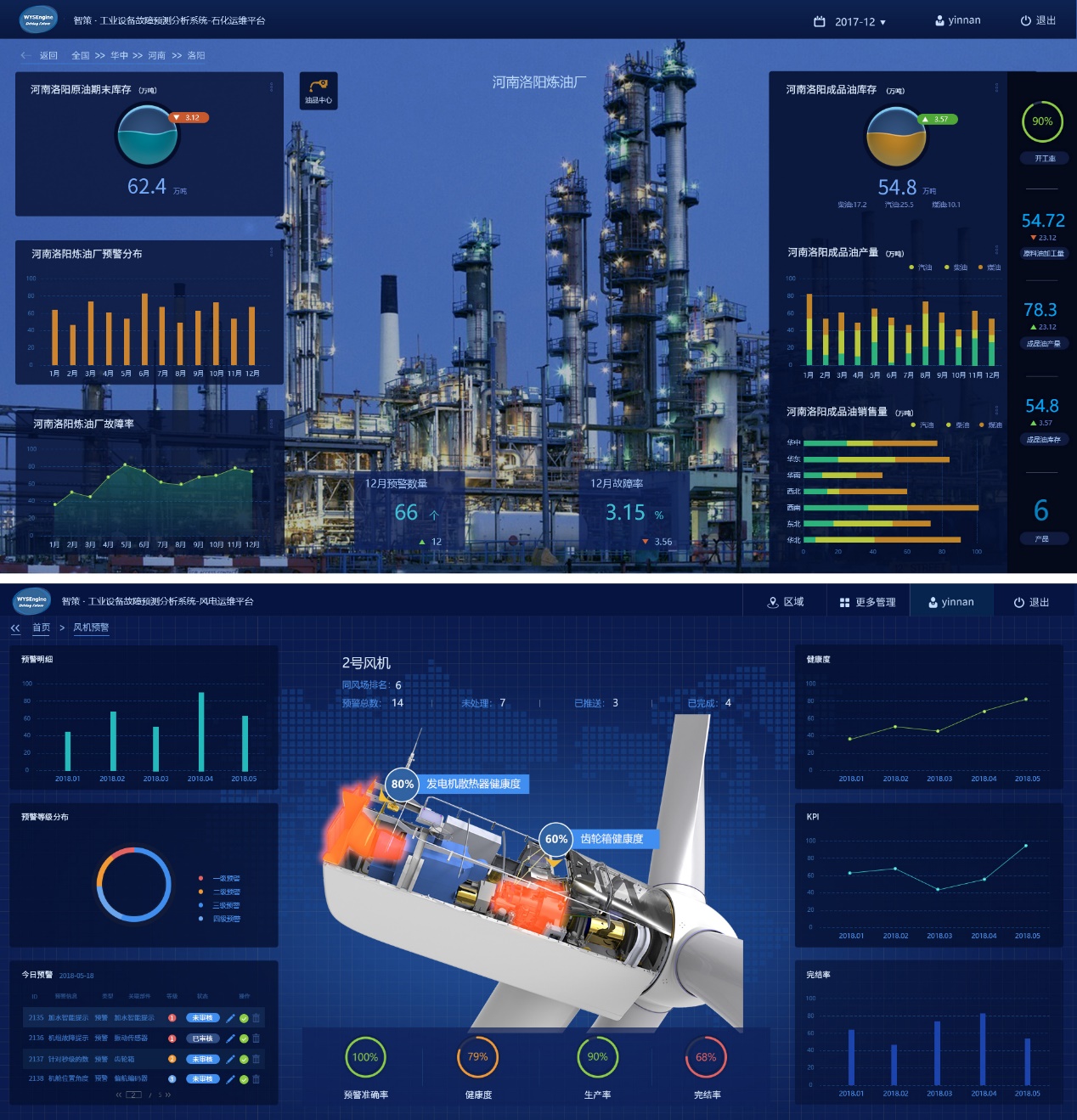
圖10 工業(yè)設(shè)備故障預(yù)測分析系統(tǒng)APP效果圖
 AII微信公眾號
AII微信公眾號
 AII頭條號
AII頭條號